




Hey ChatGPT, write me an article explaining how AI works in behavioral health.
That’s a joke, of course—ChatGPT was not involved in the writing of this article. (AI can do a lot of impressive things, but it can’t replace me as a behavioral health expert—yet.)
That said, the relatively recent release of ChatGPT brought about an explosion of all things AI-powered. This makes it feel like a newfangled innovation, but the technology behind AI is pretty well-established. In fact, I’m willing to bet you’ve been using it for years—whether you’ve searched for information on Google or purchased a “suggested item” from Amazon.
But now that AI has entered the realm of health care—particularly behavioral health care—it’s important for providers and leaders to have a firm handle on the technology behind it, especially if their knee-jerk reaction is fear.
After all, in the words of Marie Curie, “Nothing in life is to be feared. It is only to be understood.”
With that mindset in tow, let’s dive in.
What is Artificial Intelligence?
Simply defined, artificial intelligence (AI) is “a field which combines computer science and robust datasets to enable problem solving.”
But how can we really know if a system truly is “intelligent” in the same way a human is intelligent?
The Turing Test
Some of you might be familiar with the “Turing Test” developed by Alan Turing in 1950. Turing actually called this test “The Imitation Game,” and the movie of the same name was a rough semi-biography of Turing.
Here’s the premise: If a human being has a conversation with a computer and cannot discern whether the entity they’re talking to is a person or a computer, then the computer meets the criteria for having intelligence. (This is an oversimplification, but it captures the spirit of the test.)
While the Turing Test was meant to establish a benchmark for computer intelligence well before Apple was even an idea in a garage, it still has relevance decades later with the introduction of chatbots—particularly in behavioral health.
The Origin of Chatbots
Chatbots leverage AI, yes, but the way they are used is strikingly similar to the format of the Turing Test: a person interacting with a computer.
Developed in 1966, the world’s first chatbot—though no one used the term “chatbot” back then—was called ELIZA. This technology was modeled on Rogerian, non-directive psychotherapy—and not surprisingly, it wasn’t very good compared to the highly sophisticated chatbots of today. It’s worth noting, though, that in the 50-odd years since ELIZA was born, no AI has passed the Turing Test—though some have claimed to do so.
What is Machine Learning?
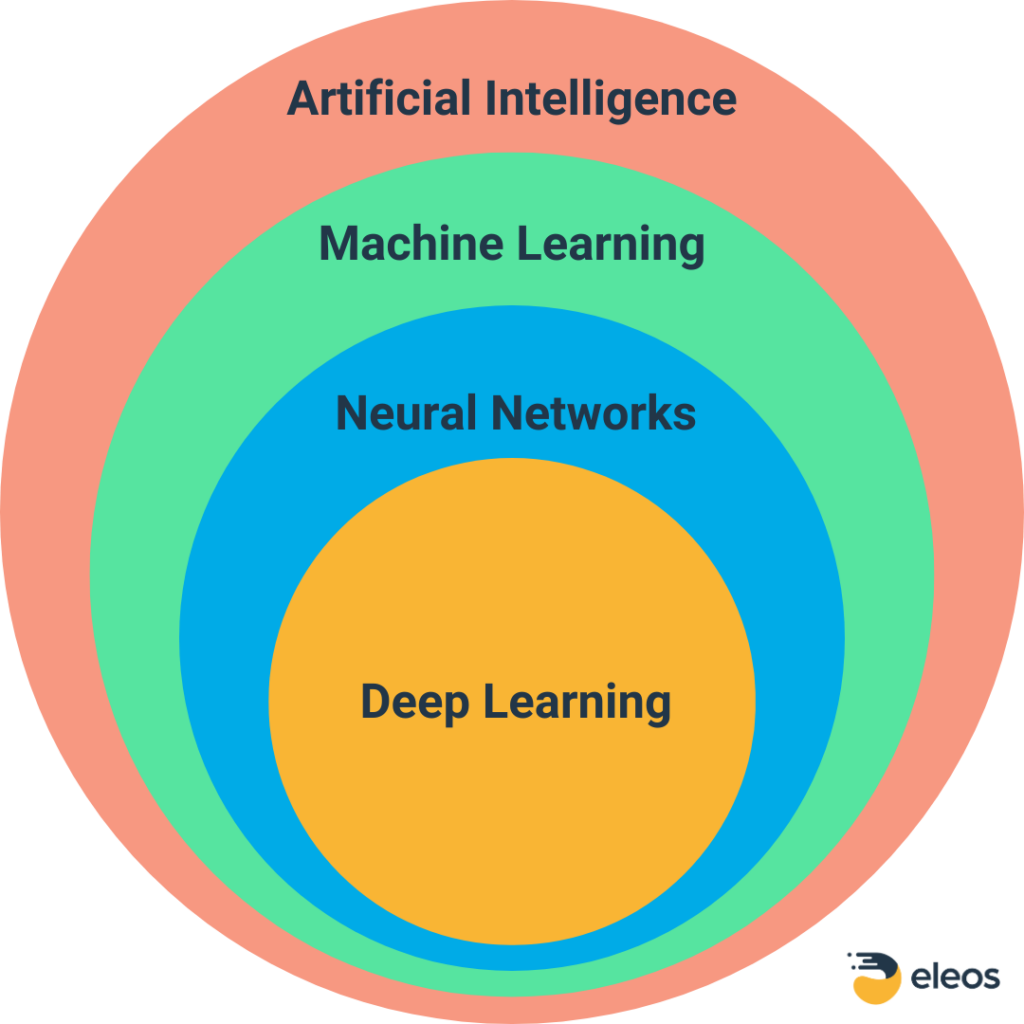
Artificial intelligence is a global term that encompasses several other terms you may recognize—including machine learning (ML), deep learning, and neural networks. Here, we will focus on machine learning—specifically, supervised machine learning—since this type of ML is at the core of most healthcare AI applications. The relationship between these different types of artificial intelligence is shown below.
Similarity to Research Design
I am a psychologist, not a data scientist. So when I started exploring AI and ML, I was struck by the similarities between the development of a workable machine learning model and the development of a clinical research project (or even the construction of a psychological test). I’ve summarized this comparison in the table below.
| Table 1. Comparison of Machine Learning, Research Project, and Psychological Test Development Steps | |||
| Step | Machine Learning | Research Project | Psychological Test Development |
| Identify question to be answered | |||
| Collect data | Create or get access to relevant databases | Recruit subjects | Select test items/questions |
| Prep/clean data | Deduplicate, deidentify, split database into Training and Evaluation datasets | Screen subjects | Eliminate items that are irrelevant |
| Choose a model | Pick the model based on whether data is image, text, or numerical; develop success criteria, ID acceptable Type I and Type II error rates | Split subject design, test-retest, time-series, quasi experimental | Correlate with existing tests, expert analysis |
| Train the system | Use experts to train the model | No good analogy | |
| Evaluate | Use Evaluation dataset to determine accuracy of the model | ANOVA, MANOVA, etc. | Assess reliability and validity |
| Tune the model | Tweak model based on first iteration vs. expectations | Run beta test | Evaluate item loading |
| Go | Initiate real-life usage | Run the study | Implement the test |
Adapted from: Gao, Y. 2017
For example: The end goal or research outcome must be defined ahead of time. Otherwise, how can the researchers know if they’ve been successful?
In a research study, we want to know things like whether an intervention is better than no intervention. In psychological test development, we want to know if the test gives us more or better information than no test or a different test.
The goal is similar for machine learning. ML analyzes a set of data and attempts to discriminate between “signal” (something that’s really there) and “noise” (randomness).
Part of why it’s called “machine learning” is that the model must be trained—and that’s the one step that differentiates ML from something like a research project or the development of a psychometric tool (although there are some similarities to developing questions for psych tests).
The ML Training Process
ML training is a critical and laborious process that involves teaching a computer the concepts it needs to know in order to achieve the desired output. For example, to create a model that specializes in identifying images of tools, experts would need to teach the computer about all the individual attributes of things like wrenches, screwdrivers, and hammers.
By doing this repeatedly with different image variations of these tools, the computer ultimately gathers enough information to be able to correctly differentiate between a wrench, a hammer, and a screwdriver every time it reviews a new image. This AI image recognition example is oversimplified for clarity, but it is fundamentally the same process used for things like facial recognition (which many of us use to unlock our smartphones) or language recognition (which is used in a variety of tools, including those specific to behavioral health).
If you substitute words for images, the process is the same. Data scientists build initial models by training large data sets from a variety of sources (e.g., real-world psychotherapy sessions) on spoken words.
These words are first converted from audio to text using a tool called Automatic Speech Recognition. The text is then analyzed using a tool called Natural Language Processing (NLP)—not to be confused with Neuro Linguistic Programming.
You can learn more about this process—including how we use it to develop our AI tools at Eleos—here and here.
What is Natural Language Processing?
In the context of AI and ML, NLP is a translator of sorts. It takes voice and text and converts it into a format the computer can recognize and use. Voice dictation—which allows you to give commands to Siri, Alexa, and many GPS systems—is one of the simplest forms of NLP. These technologies have gotten so good that typically, you don’t even have to “train” the system to recognize your specific voice.
That said, users of dedicated voice-to-text applications like Dragon Dictate know that training the AI in your voice can be beneficial, as it enhances the AI algorithms even further to discern nuances in your voice, ultimately making the output more accurate.
The Nuance Factor
Speaking of nuance: One interesting thing about NLP is that it’s able to not only translate spoken words into written words—in multiple languages, in the case of Eleos—but also capture more contextual aspects of language like intent, sentiment, and intonation. As you can imagine, these variables are crucial when the context of a conversation is just as important as the content—as is almost always the case in behavioral health.
On that note, it’s important to recognize that when AI and ML focus on language, the training and development process is much more technologically complex than a process dealing with images or other source data. That’s because the meaning of language is so nuanced compared to other inputs. It’s also why healthcare AI has focused mainly on image recognition (e.g., in the fields of radiology, dermatology, and microbiology) rather than more language-intensive fields like psychotherapy.
While speech recognition has been used in medicine for years, it has largely been limited to dictation through applications like Dragon Dictate. And even though chatbots are gaining popularity in behavioral health, they are mainly consumer-facing tools.
But newer AI tools are now emerging to help providers be better in their jobs by providing insights into clinical processes while also expediting documentation—and many behavioral health providers have already started using these tools.
Special Requirements for Behavioral Health AI
So, how do these provider-focused behavioral health AI systems work? As mentioned earlier, ML requires experts to be able to train a system in the domain of choice. Going back to the image example, if a system is designed to help radiologists by screening X-rays to identify signs of cancer, then the experts training the AI will likely be experienced radiologists who can tell the models “this is cancer” and “this is not cancer.”
The same is true for behavioral health-specific AI systems. As in the case of a traditional clinical research project, data scientists set minimum standards for things like recall and precision. In essence, they determine how good is “good enough” and define the acceptable Type I (false positive) and Type II (false negative) error rates. If you have a background in psychometrics, then you might notice the similarity to determining acceptable validity and reliability levels when developing psychological tests.
Building and Testing the Base Model
Construction of the research questions in machine learning falls under the purview of data scientists in the same way that test validity and reliability falls under the purview of psychometric experts. Data scientists and clinical experts look at a sentence and identify whether it’s written in the best way to convey a clinical point. This process is repeated many times so that the system can differentiate between things that are relevant to clinicians and things that are not.
Over many training episodes, the model gets better and better until it is sufficiently trained to accurately discriminate these and myriad other variables of interest—each of which must be trained. Think of this predetermined level of accuracy like you would a desired significance level in a research study. In both cases, the goal is to reach a specified probability level.
Through this process, the base model is built. That model is then tested with a portion of the original training database that has been set aside specifically for this purpose. Data analysts and clinical experts will then tweak the model for improved accuracy, similar to clinical researchers running an analysis—say, a multivariate analysis of variance (MANOVA)—to add and delete variables until the maximal amount of variance can be accounted for. Once this step is completed and the model passes muster, it’s ready for general release to the real world.
Avoiding Bias
All responsible providers of AI technology and psychological tests should be concerned about the potential ethical ramifications of their creations. The population on which a psychological test is normed must be diverse—otherwise, you risk the introduction of bias.
The same is true for AI. The data used to construct the base model for any AI must be heterogeneous to mitigate potential bias. Most tests and AI tools do this well, but there are examples of biases slipping into both.
Similar to any other education process, the training of the model is only as good as the data it’s based on. The old maxim “garbage in, garbage out” still applies to these advanced technologies.
That’s why behavioral health providers who are exploring AI tools must intentionally seek out those that have been trained with a large quantity of reliable, diverse real-world behavioral health data—which is exactly what the development team at Eleos has committed to. (By contrast, general use systems like ChatGPT have been trained on general data—meaning they can’t reliably generate output that is clinically relevant and free of bias.)
Even though AI has been around for a long time, we’re barely scratching the surface of what is possible with this technology in the realm of health care—especially behavioral health care. And by taking the time to truly understand everything that goes into making it work—and ensuring the relevance and reliability of its output—we can dispel some of the fear that comes with using any new technology.
Check out this blog post to learn even more about the inner workings of Eleos Health’s purpose-built technology, and get up to speed on the science behind our AI here.
Interested in seeing our behavioral health-specific AI in action? Request a personalized demo of the Eleos platform here.
